Overview
The design system ran on React, TypeScript, Vite, SCSS and Storybook 10. It had 91 active components and real brand assets. It was readable to humans. But not to AI agents.
Most design systems look the same to an AI agent: a directory of component files and a Storybook URL. Useful intent lives in tribal knowledge, design review comments and the heads of the people who built the thing. An agent landing in the repo would have to grep source files, guess at the API and invent a layout.
I built the substrate, the machine-readable layer agents read before doing anything: AI.md, manifest.json, tokens.json, usage docs and patterns. Now there is a machine-addressable surface any AI agent can query without crawling source code and without depending on any specific AI tool.
My contribution
Strategy / Engineering / Writing / Roadmap
The team
Me / Myself / I

Process
The strategic bet
Most "AI for design systems" conversations pick a tool first, then try to make the system fit it. The result is brittle. Tools change. Vendors come and go.
The better question is the inverse: what does my design system look like to an AI agent today, and what's the minimum I'd need to add to make it legible? My answer: don't pick a tool. Make the system discoverable as data, and let whichever tools win read it.
Making the system addressable
AI.md at the repository root. It tells any agent landing in the repo what's there and where to find it. Short. One screen.
Underneath it, an ai/ directory with two structured files. tokens.json covers color, type, spacing, radius, elevation and motion. manifest.json catalogs every component: name, category, source path, stories path and a purpose line for the most-used components. An agent reading the manifest can answer "what components exist" without touching the file tree.
Usage docs: the missing layer
Most design system docs share the same gap. They explain how a component works, not when to use it. A Button properties table tells you the variants. It doesn't tell you when to use primary over outline.
I wrote 91 docs, one per active component. Each follows the same structure: purpose, when to use, when not to use, common mistakes, a real-world example and a link to the typed API. The "when not to use" section is where tribal knowledge becomes portable guidance. "Don't use two primary Buttons side by side" is the kind of rule that previously lived in design review comments and nowhere else.
That's 100% coverage of the active component surface.
Patterns: the layer above components
Component docs answer "how do I use Button?" They don't answer "how do I build a marketing landing page?" I added ai/patterns.json with 11 canonical compositions: six page-level patterns and five section patterns. Each entry lists the components it uses, points at a sample page and links to a full doc with working code samples.
Code samples turn the pattern doc from descriptive into generative. An agent reading it gets a working starting point, not a structural diagram.
Audits: surprising finds
Seven scripts wired into npm run audit. They find hardcoded colors not in the token JSON, components without usage docs, broken manifest references, inline styles and drift between the pattern layer and sample pages.
The first runs were educational in ways I didn't plan for. One found a parallel token source with 35 hex values that had quietly drifted from the main one. Another surfaced 22 component folders missing from the manifest entirely. A cross-layer audit found 13 components appearing in sample pages but not in any pattern, which drove three new pattern docs.
The audits weren't designed to find those things. They found them anyway. A design system with a machine-readable surface gains that governance capacity without asking for it. Without one, the drift stays invisible.
MCP: A Live Interface for Client-Resident Agents
Some agents prefer a typed tool call to a file read. I wired the system as a live MCP server at /mcp on the same Storybook domain, powered by @storybook/mcp and deployed as a Cloudflare Pages Function on the same deploy.
Four tools: three documentation tools from @storybook/mcp (list all components, get component docs, get story detail) and one I built that returns a rendered Storybook URL given a story ID and optional custom props. An agent can show a user exactly what its suggestion looks like, without writing or running code.
Proof it works
Claude Desktop, connected to the MCP server and Figma's API. I asked it to compose the Marketing Landing pattern.
It read the manifest, the token JSON, the pattern doc and the prop interface for each component it needed. Then it built the page in Figma using real component instances bound to my actual semantic color and text styles. Five Button instances across the page. Edit the Button once, all five propagate.
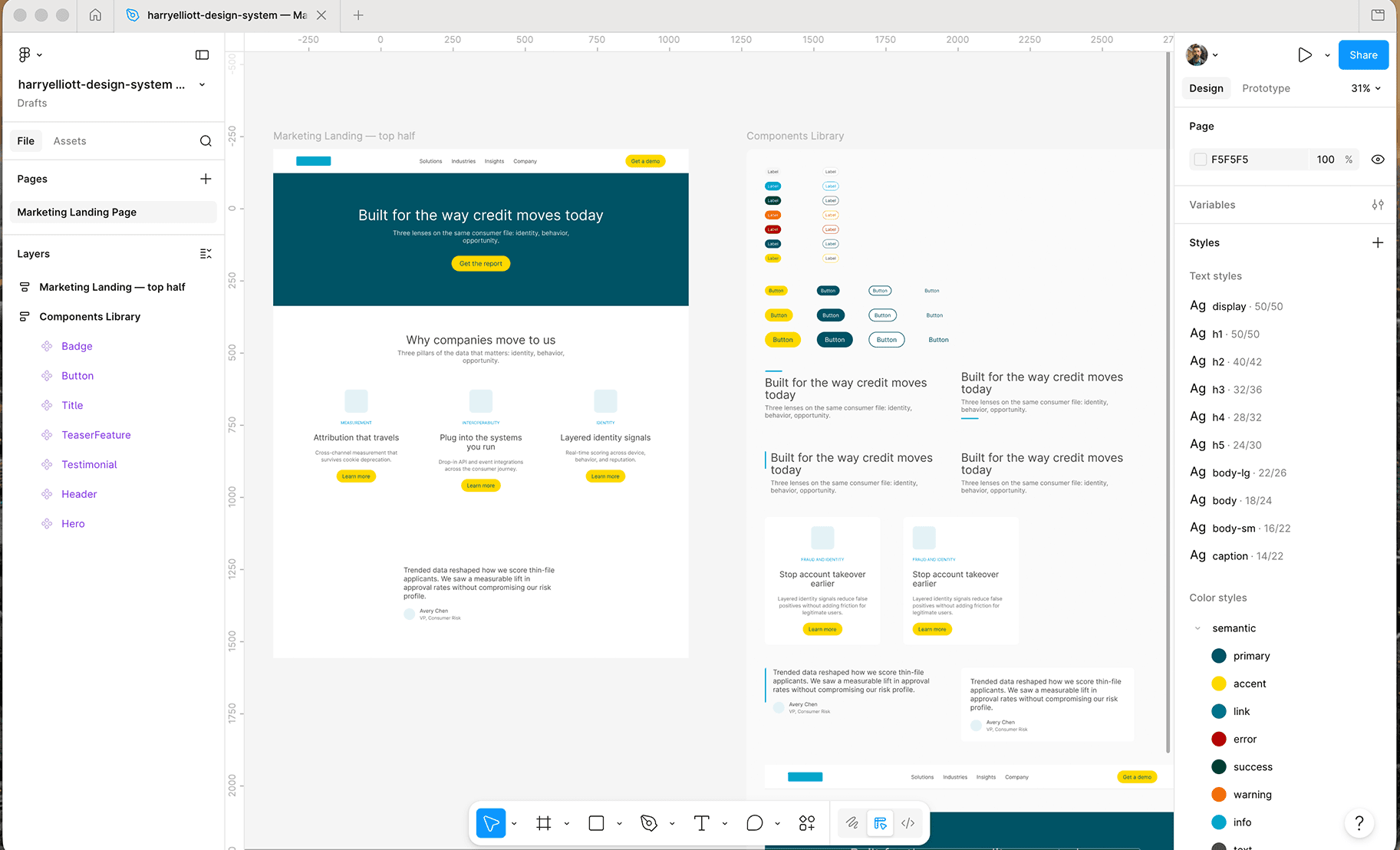
Nothing was traced. There were no screenshots. Every fill, stroke and text value resolved to a real token. Without the manifest, the agent would have grepped source files and guessed at the API. Without tokens.json, it would have hardcoded colors. Without the pattern doc, it would have invented a layout. The substrate carried the demo.
Outcome
AI.md at the root serves as the entry point. The ai/ directory holds the queryable layer: a manifest of 97 components (91 active, 6 legacy), a DTCG-inspired token structure, 91 usage docs, 11 pattern docs with working code samples and a cross-reference index over the whole thing. Seven audits and three generators enforce integrity and keep derived outputs in sync. The MCP server lives at /mcp on the Storybook domain.
Two surfaces, one substrate. Static files for repo-resident agents. MCP for client-resident agents.
The opportunity in AI right now isn't "use it to make a thing." It's "structure your thing so AI can read it." The systems that aren't doing this will be obvious within a year.
What's Next
The Figma demo surfaced three gaps. Typography belongs in tokens.json: the type scale lives in SCSS mixins today, so an agent working in Figma has to read source to learn it. The system needs a font mapping layer for Figma specifically, where commercial faces aren't accessible via the Plugin API. And the MCP needs a get-tokens tool so all three layers resolve through one protocol instead of two.
Each is one focused commit.